3강) Python(파이썬) 알고리즘에 대해서
이전에 사용하던 Visual Studio 사용 / 파이썬에서의 알고리즘
궁금한 점 : 코드를 전체적으로 배운 뒤에 자바를 사용하다가 파이썬을 사용하면 혼동이 심한지?
전체적인 틀은 같은지 궁금함
처음에 깔 때가 아닌 깔려있는 상태에서 파이썬 구축하는 방법은 강의에 나와있지 않음.
이렇습니다.로 끝나는 경우가 많아 이해가 어렵고 불친절함 / 유튜브 강의가 훨씬 나을 것 같다는 생각이 듬
Visual Studio 실행 - 도구 - 도구 및 기능 가져오기(T)로 들어가서 Python 개발 체크


설정 후 수정(이미 설치된 상태에서 새로 설치할 경우 수정으로 뜸)
언어팩에서 영어 체크 돼 있는지 확인하기
Visual Studio를 통한 Python 사용




간단하게 print("Hello Python") 만 입력하면 실행됨 print("Hello Visual Studio" 등
굉장히 간단하게 사용 가능
우측 솔루션 탐색기에 PythonNote (내가 만든 파이썬 파일) 오른쪽 클릭 - 추가 - 새 항목 -

print("안녕하세요. 파이썬")py 파일 - 오른쪽 클릭 - 시작 파일로 설정 후 Ctrl + F5를 하면 먼저 시작파일로 설정된 파일이 있으면 먼저 나옴
(아까 넣었던 hello python을 시작파일로 설정하면 현재 안녕하세요. 파이썬이 아닌 저게 먼저 나옴)
github와 같은 소스 저장소를 이용하는 경우가 많음
확장 - 확장 관리 - 온라인(좌측) - GitHub Extension for Visual Studio 이용
(검색 : Github를 이용하는게 편함)
예전 강의라 달라짐 현재 visual studio 버전에는 저게 없음
기본적으로 연동 돼 있는 것으로 확인됨
상단에 Git 누르고


로그인 등을 통한 연동 필요
GitHub: Let’s build from here
GitHub is where over 100 million developers shape the future of software, together. Contribute to the open source community, manage your Git repositories, review code like a pro, track bugs and fea...
github.com
회원가입 후 연동하면 됨

회원가입 및 로그인 연동 및 올렸을 때 - 동기화

업로드하면 저장 돼 있는 것을 확인할 수 있음 (앞은 아이디)
또한 우측에 있는 솔루션 탐색기를 우클릭해서 Git을 통해 사용 가능

다른 컴퓨터에서 Visual Studio로 Git에 올렸던 파일 가져오기
처음 Visual Studio 실행 - 리포지토리 복제 - 내가 git 사이트 홈페이지 주소 가져오기
https://github.com/Pear1yCode/PythonNote


깔끔하게 전부 생겨남
(간단하게 백업을 인터넷에 해놓는다고 생각하면 되며 사용 후 저장해놓고 다른 컴퓨터에서 사용할 때도 편리하게 가져올 수 있도록 쓸 수 있는 방법)

동기화 버튼 등을 잘 사용하고 다른 사람이 동기화 후 올라왔을 때 페치를 통해 업데이트 해줄 수 있음
(팀 탐색기가 있을 때)
지금은 Git 변경 내용을 사용하는지는 모르겠다.
코멘트 등도 달 수 있음
강의가 2019라 옛날 강의라 조금 다름

페치, 풀, 푸시, 동기화 등을 잘 이용하면 좋을 것 같다.
https://learn.microsoft.com/ko-kr/visualstudio/version-control/git-fetch-pull-sync?view=vs-2022
git 페치, 풀, 푸시 및 동기화 - Visual Studio (Windows)
Visual Studio에서 가져오기, 가져오기, 푸시 및 동기화를 수행하여 Git 또는 Azure DevOps를 사용하여 프로젝트의 버전 관리를 수행하세요.
learn.microsoft.com

우측 하단에 있는 분기 - master 등을 이용할 때 잘 나눠서 사용
변경된 내용 커밋 - 푸시 - 페치 - 끌어오기
페치는 patch(패치)가 아닌 fetch임
알고리즘과 절차 지향 프로그래밍 강의 소개 (중복 생략)
회사마다 알고리즘이 다르고 쉽고 어려운 알고리즘이 나뉘고 그 중에 알아두면 도움이 되는 쉬운 알고리즘
알고리즘 = 문제 해결 능력
입력(Input) - 처리(Process) - 출력(Output)
알고리즘 = 풀이법 (프로그래밍에서의 문제 풀이법 - 문제해결을 위한 방법)
입력 = 자료 구조 및 자료가 놓이는 곳
처리 = 알고리즘 처리 영역 (핵심)
출력 = 우리가 보는 UI
순서도는 나중에 공부 (기사 공부 시)
학습할 알고리즘 리스트 및 강의 소스 다운로드 (중복 생략)
합계, 개수, 평균, 최댓값, 최솟값, 근삿값, 순위, 정렬, 검색, 병합, 최빈값, 그룹 알고리즘
Sum, Count, Average, MAX, MIN, Near, Rank, Sort, Search, Merge, Mode, Group
합계 알고리즘 (Sum Algorithm)



파이썬이 비교적 쉬운듯함
#[?] n명의 점수 중에서 80점 이상인 점수의 합계
# 합계 알고리즘 (Sum Algorithm) : 주어진 범위에 주어진 조건에 해당하는 자료들의 합계
#[1] Input : n명의 점수
scores = [100, 75, 50, 37, 90, 95]
sum = 0 # 합계가 저장될 그릇
N = len(scores) # 의사코드(슈도코드)
#[2] Process : 합계 알고리즘 영역 : 주어진 범위에 주어진 조건(필터링)
for i in range(0, N): # 주어진 범위
if scores[i] >= 80: # 주어진 조건
sum = sum + scores[i] # SUM
#[3] Output
print(f"{N}명의 점수 중 80점 이상의 총점: {SUM}")이상하게 이렇게 나옴
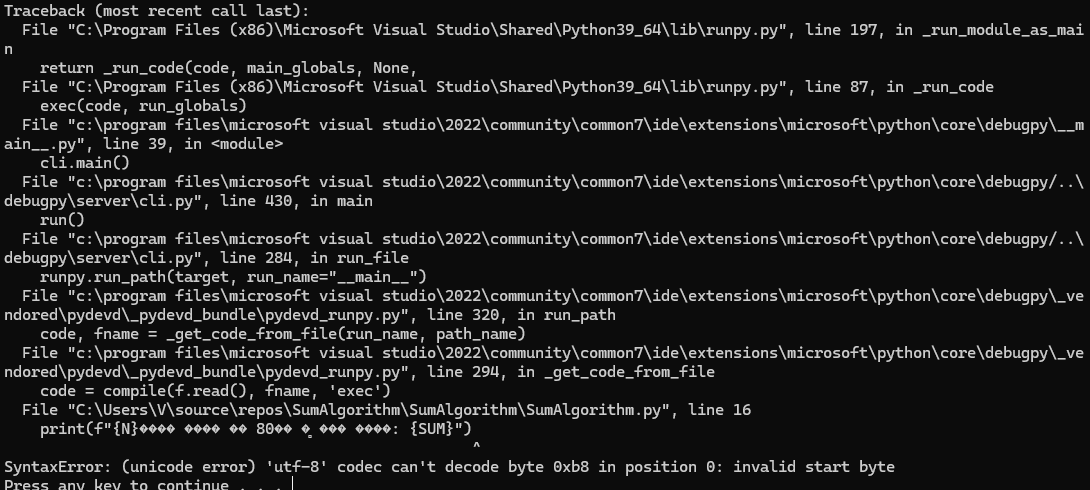
배우기 참 어렵다.
오류가 많아서 뭘로 해결해야하는지는 나오지 않기 때문에 문제가 생기거나 설치 부분은 다 직접 알아내야한다.
잘 모르겠어서 Visual Studio code로 옮겼다.

좌측 확장을 누르고 python 검색 후 3개를 설치했다.

여기서는 정상적으로 작동하지만 조금 다른 부분이 마지막 부분의
print(f"{N}명의 점수 중 80점 이상의 총점: {SUM}") 부분의 SUM을 소문자로 변경해야 작동함 sum
Visual Studio 디버거 기능을 사용하여 알고리즘 소스 분석 및 학습
"타이핑 및 결과 확인 그리고 이해하려고 노력 (+ 디버깅 && 디버거)"
process 부분에서 중단점 생성 및 한줄씩 코드 실행
process를 해보면 한번에 다 되는게 아니라 그 줄이 반복되면서 값이 생성됨
중단점 생성 후 한줄씩 계속해보면 한줄씩 되면서 값이 합쳐지고 생성됨
#[!] 디버거 사용하기: F9 -> F5 -> F11 -> F5 를 통해 확인 (Visual Studio 기준)
Visual Studio Code는 키는 조금 다르지만 내용은 같으니 똑같이 하면 됨
등차수열(연속하는 두 수의 차이가 일정한 수열)
일정한 규칙(연속하는 두 수의 차이가 일정함)이 있는 수열을 뜻하는 등차수열
Arithmetic Sequence.py 생성
#[?] 1부터 20까지의 정수 중 홀수의 합을 구하는 프로그램
# 등차수열 (Arithmetic Sequence) : 연속하는 두 수의 차이가 일정한 수열
#[1] Input
sum = 0
#[2] Process
for i in range(1, 20): # 주어진 범위
if i % 2 != 0: # 주어진 조건 : 필터링(홀수)
sum = sum + i
print(sum, end='\t')
#[3] Output
print(f'1부터 20까지의 홀수의 합: {sum}')
이상하게 나와서 수정함
#[?] 1부터 20까지의 정수 중 홀수의 합을 구하는 프로그램
# 등차수열 (Arithmetic Sequence) : 연속하는 두 수의 차이가 일정한 수열
#[1] Input
sum = 0
#[2] Process
for i in range(1, 20): # 주어진 범위
if i % 2 != 0: # 주어진 조건 : 필터링(홀수)
sum = sum + i
print(i, end=', ')
#[3] Output
print(f'1부터 20까지의 홀수의 합: {sum}')
개수 알고리즘 (COUNT Algorithm)
#[?] 1부터 1,000까지의 정수 중 13의 배수의 개수(건수, 횟수)
# 개수 알고리즘(Count Algorithm) : 주어진 범위에 주어진 조건에 해당하는 자료들의 개수
# 반복과 계산이 빠른 컴퓨터에게 시키는 효율성 좋은 알고리즘
# [1] input
count = 0 # 0으로 초기화 - 개수를 저장할 변수는 0으로 초기화
# [2] process : 개수 알고리즘 영역 : 주어진 범위에 주어진 조건(필터링)
for i in range(1, 1000):
if i % 13 == 0: #주어진 조건: 13의 배수면 개수 증가
# count = count + 1
count += 1 # COUNT
# [3] output
print(f'1부터 1,000까지의 정수 중 13의 배수의 개수: {count}')나는 그냥 아래에 있기만 하면 되는줄 알았으나 들여쓰기를 제대로 하지 않으면 값이 정상적으로 출력되지 않았다.
process 부분 아래의 for, if, count 구문을 보면 아래로 갈수록 들여쓰기를 해야 정상적으로 값이 출력됐다.
이렇게만 돼 있어도 문제 발생
if와 count를 들여쓰지 않으면 문제 발생
count도 들여쓰기를 해야 함
for 가장 앞, if는 tab 한번, count는 tab 두번 후 정상적으로 출력됨 (정상적인 코드 및 출력)
평균 알고리즘 (Average Algorithm)
새로운 알고리즘이 아닌 합계 / 개수(합계를 개수로 나눈 것) 알고리즘
잘 모르겠으나 일단 강의를 들어보면 != 는 아니다를 뜻하고 ==는 맞다를 뜻하는 것 같다.
if sum == 0 or count == 0은 만약에 sum 값이 0 이거나 count 값이 0일 때를 뜻하고
if sum != 0 or count != 0은 만약에 sum 값이 0 이 아니거나 count 값이 0 이 아닐 때를 뜻한다.
(당연하지만 or을 and로 변경할 수 있음)
저번에 찾아봤을 때 ==의 의미가 내가 아는 =와 다르다고 생각했는데 착각이었던건지 또 여기서는 =와 같은 느낌인데
여기서 드는 궁금한 점은 =로 안하고 왜 ==를 사용하는지(값이 아닌 코드에서의 등호는 ==로 쓰는 것일까?) 궁금했다.
추가로 궁금한 점이 그리고를 표시할 때 &&를 사용하는데 이것도 왜 &가 아닌 &&로 두개를 사용하는지도 궁금하다.
파이썬의 경우에는 &&는 안되지만 다른 곳에서의 &&를 두개쓰는게 궁금했다.
파이썬에서는 //가 아닌 #를 사용해야 주석처리를 할 수 있으며 ;가 아닌 :를 사용한다.
하지만 :만 사용할땐 사용하고 ;를 사용하기도 함(주로 값에서)
어떻게 보면 더 쉽게 만들어진 느낌이 강하지만 방식이 달라서 참고가 필요하다.
#[?] n명의 점수 중에서 80점 이상 95점 이하인 점수의 평균
# 알고리즘 (Average Algorithm) : 주어진 범위에 조건에 해당하는 자료들의 평균
#[1] input
data = [ 90, 95, 78, 50, 95 ]
sum = 0 # 합계 담는 그릇
count = 0 # 개수 담는 그릇
N = len(data) # 의사코드(슈도코드)
#[2] process : AVG = SUM / COUNT
for i in range(0, N):
if data[i] >= 80 and data[i] <= 95: # 주어진 조건
sum += data[i] # SUM
count += 1 # COUNT
avg = 0.0
if sum != 0 and count != 0:
avg = sum / count # Average
#[3] output
print(f"80점 이상 95점 이하인 자료의 평균: {avg:.2f}")참고할 부분
1. and를 &로 변경하면 제대로 나오지 않음
2. 마지막 output 부분의 print(f "내용: {내부 괄호가 ()가 되면 안됨}) -괄호 실수로 다른 괄호 사용하지 않도록 주의
최댓값 알고리즘 (MAX Algorithm)
이번엔 main 함수로 불러와서 한다고 함 (뭔말인지 모르겠다. 갑자기 바꿔서 한다고 하셨다.)
입문자는 복사해놓고 사용할 수 있는 기능으로 복사해놓으면 편하다고 함
MAX와 MIN에서는 초기화 영역을 사용 [0] Initialize 부분
궁금한 점 : 의사코드는 뭐고 왜 사용하는 걸까 / 항상 같은지? 0부터 N까지의 수라고 나열했을 때 그거에 대한 설명?
(의사코드는 N을 할당하는 느낌이 강하다. 그냥 N을 넣으면 코드 디버깅 시 N이 정의되지 않았다고 오류가 뜸)
print f에서 " "를 사용할 때와 ' '를 사용할 때의 차이 (왜 알고리즘마다 달라지는 것인지)
#[?] 주어진 데이터 중에서 가장 큰 값
import sys
# 최댓값 알고리즘 (MAX Algorithm) : (주어진 범위 + 주어진 조건)의 자료들의 가장 큰 값
def main():
#[0] Initialize
max = -sys.maxsize - 1; # 숫자 형식의 데이터 중 가장 작은 값으로 초기화
#[1] Input
numbers = [ -2, -5, -3, -7, -1 ] # MAX : -1
N = len(numbers) # 의사코드(슈도코드)
#[2] Process : MAX
for i in range(0, N): # 주어진 범위
if numbers[i] > max: # 더 큰 데이터가 있다면
max = numbers[i] # MAX Algorithm : 더 큰 값으로 할당
#[3] Output
print(f'최댓값: {max}')
if __name__=="__main__":
main()visual studio code에서는 제대로 안나오는데 문제가 있는 것 같다.
제대로 환경 구축이 안된 것으로 보인다.
마지막 부분의
if가 가장 앞이 아니라 띄어져 있었는데 값이 제대로 출력되지 않았다.
이렇게 하니 제대로 출력됨 / 무슨 차이일까 / 들여쓰기와 관련있는 것인지?
추가로 visual studio code라서 그런것인지 궁금함.
최솟값 알고리즘 (Min Algorithm)
궁금한 점 : %연산자로 나눈다는 의미와 /로 나누는거랑 차이, 둘 다 나누는 것 같은데 뭐가 다른지 모르겠다.
#[?] 주어진 데이터 중에서 가장 작은 [짝수] 값
import sys
# 최솟값 알고리즘(Min Algorithm) : (주어진 범위 + 주어진 조건)의 자료들의 가장 작은 값 / MAX에서 반대
def main():
#[0] Initialize
min = sys.maxsize # MAX는 최솟값으로 MIN은 최댓값으로 초기화하는 과정 - 숫자 형식의 데이터 중 가장 큰 값으로 초기화
#[1] Input
numbers = [2, 5, 3, 7, 1]; # MIN : 1 -> MIN : 2(짝수) - 가장 작은건 1이지만 짝수로 나와야 하므로
N = len(numbers) # 의사코드 (슈도코드)
#[2] Process
for i in range(0, N):
if numbers[i] < min and numbers[i] % 2 == 0: # 짝수 최솟값
min = numbers[i] # MIN : 더 작은 값으로 할당
#[3] Output
print(f"짝수 최솟값: {min}")
if __name__=="__main__":
main()근삿값 알고리즘 (NearAlgorithm)
여기까지 하면서 느낀거지만 아무것도 모르고 듣고있지만 1프로 정도 흐름이 조금씩 이해가 되기 시작했다.
사실 아직도 뭐가 뭔지는 모르겠지만 조금씩 이런 느낌이라는 흐름이 이해된다.
여기서 디버깅을 하면 오류가 뜬다. 여기서 뜨는 오류는

N이 정의되지 않았다인데 여기서 쓰이는데 의사코드(슈도코드)로 보인다.
input에 N=len(numbers)를 넣어주면 해결된다.
#[?] 원본 데이터 중에서 대상 데이터와 가장 가까운 값
import sys
# 근삿값 알고리즘 (Near Algorithm) : 가까운 값 = 차잇값의 절댓값의 최솟값 / 절댓값으로 변경해도 차이 자체는 상관없기 때문에
def main():
#[0] initialize
min = sys.maxsize # 차잇값의 절댓값의 최솟값이 담길 그릇 - 처음에는 max = 99999로 놓고 위에 import sys를 넣고 sys.maxsize를 사용한다.
#[1] input
numbers = [10, 20, 30, 27, 17]
target = 25 # 25로 지정했을 때 차이가 2인 27이 나옴 / target 과 가까운 값
near = 0 # 가까운 값 : 27이 나오게 할 곳
N = len(numbers) # 의사코드 (슈도코드)
#[2] process
for i in range(0, N):
_abs = abs(numbers[i] - target) # 차잇값의 절댓값 = 빼면 플러스든 마이너스든 절댓값으로 변경하면 그 값과의 차이가 나옴
if _abs < min:
min = _abs # MIN : 최솟값 알고리즘
near = numbers[i] # NEAR : 차잇값의 절댓값의 최솟값일 때의 값
#[3] output
print(f"{target}와/과 가장 가까운 값: {near}(차이: {min})")
if __name__=="__main__":
main()아직 하나도 모르겠지만 알수록 재밌는 것 같다.
순위 알고리즘 (Rank Algorithm)
항상 궁금한 것인데 왜 초기화과정이 필요한 것인지? - 초기화를 해야 코드 적용 시 공평하게 적용되기 때문인 것인가?
(코드가 복잡해지지 않도록 하는 것? - 초기화하지 않으면 코드를 짤 수 없을 것 같기도?)
1등으로 초기화 시켜놓고 1씩 값을 추가하는 방식의 코드를 만들기 위함이라 그런게 아닐까?
그리고 여기서 마지막에 print f에 scores에 들어가는 3은 무슨 의미인것인가? (글씨 줄 맞추기?)
파이썬이 아닐때도 %3d등이 뭔지 잘 모르겠다.
+=은 무슨 뜻인지 모르겠다.
(+=1이라고 하면 1씩 증가한다는 의미같다.)
# 메인 함수
def main()
if __name__=="__main__":
main()메인 함수 잘 알아두기 (앞은 name이고 뒤는 main)
if와 __name__ 사이에는 공백이 있음(공백이 없으면 오류 발생)ㅓ
#[?] 주어진(지정한 범위) 데이터의 순위(등수)를 구하는 로직
# 순위 알고리즘 (Rank Algorithm) : 점수 데이터에 대한 순위 구하기
def main():
#[1] Input
scores = [90, 87, 100, 95, 80] # 등수로 변경했을때 3, 4, 1, 2, 5로 나올 것
N = len(scores) # 의사코드(슈도코드)
rankings = [1] * 5 # 모드 1로 초기화
#[2] Process : RANK Algorithm 적용
for i in range(N):
rankings[i] = 1 # 1등으로 초기화, 순위 배열을 매 회전마다 1등으로 초기화
for j in range(N):
if scores[i] < scores[j]: # 현재(i = 나)와 j(나머지들) 비교
rankings[i] += 1 # RANK : 나보다 큰 점수가 나오면 순위 1 증가
#[3] Output
for i in range(N):
print(f"{scores[i]:3}점: {rankings[i]}점")
if __name__=="__main__":
main()i나 j를 대문자로 표기하지 않았는지, 의사코드에는 N으로 아래에서는 n으로 설정하지 않았는지 체크
디버거를 통해 어떤 흐름인지 파악해보기
선택 정렬 알고리즘 소개 (프로그래밍 공통 이론)
알고리즘 중 가장 중요하다고 할 수 있는 정렬 알고리즘 (Sort Algorithm)
오름차순, 내림차순
방식에 따라 왼쪽에서 오른쪽으로 나열되는 수열
정렬 알고리즘 (Sort Algorithm)
오름차순(>), 내림차순(<)에 따른 부등호방향과 process 부분의 코드 모양을 외우는게 좋음
중요한 부분 : SWAP 알고리즘 코드
한줄로 표현했을 경우
외워두면 좋음 / 특히 정렬 알고리즘에서 도움됨 (스왑 알고리즘 코드를 쓰면 데이터가 정렬이 돼서 출력)
이걸 넣으면 3, 2, 1, 5, 4였던 결과값이 1, 2, 3, 4, 5로 정렬 돼 나타남


#[?] 무작위 데이터를 순서대로 [오름차순ASC|내림차순(DESC)] 정렬
# 정렬 알고리즘 (Sort Algorithm) : 가장 [작은|큰] 데이터를 왼쪽으로 순서대로 이동
def main():
#[1] input : Data Structure(Array, List, Stack, Queue, Tree, DB, ...)
data = [3, 2, 1, 5, 4] # 정렬되지 않은 데이터 numbers = [3, 2, 1, 5, 4]로 입력해도 됨 이름을 넣어주는건 내 자유 다만 다른 곳에서도 numbers를 사용해야 함
N = len(data) # 의사코드(슈도코드) 형태로 알고리즘 표현을 위함
#[2] process : Selection Sort(선택 정렬) 알고리즘
for i in range(0, N - 1) : # i = 0 to N - 1
for j in range(i + 1, N): # J = i + 1 to N
if data[i] > data[j]: # 부등호 방향: 오름차순(>), 내림차순(<)
temp = data[i]; data[i] = data[j]; data[j] = temp # SWAP
#[3] output : UI (Console - 우리가 현재 보고있는 console창(가장 간단)-디버깅 화면, Desktop, Web, Mobile, ...)
for i in range(N):
print(data[i]) # print(data)
if __name__=="__main__":
main()한 단계씩 계속 바뀌어 나가면서 반복하여 1, 2, 3, 4, 5로 출력됨
한단계씩 디버깅해보면 많은 반복 단계를 거쳐 나오는 것을 알 수 있음
우리는 반복작업이 오래걸리지만 컴퓨터는 코딩을 해놓으면 순식간에 노가다같은 작업을 하여 빠르게 출력 가능하므로
코딩을 사용
프로그래밍에서는 암기를 하라고 하지 않지만 외워두면 도움이 됨
이해해서 할 단계가 아직은 아니므로 외우기 권장
검색 알고리즘 소개 및 이진 검색 알고리즘 이론 (중복 생략)
순차검색은 굉장히 효율이 떨어지므로 사용하지 않는 것을 권장
이진 검색 알고리즘이 효율적이며 주라고 볼 수 있고 중간 인덱스 찾는게 핵심
이진 검색 (Binary Search) = 나누기 및 정복 (Divide and Conquer) 알고리즘
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 까지의 숫자에서
다음과 같이 레코드가 구성되어 있을 때, 이진 검색 방법으로 14를 찾을 경우 비교되는 횟수는? 이라고 했을 때
1회전 : 0 + 14 / 2 =7번째 인덱스의 값인 8
2회전 8 + 14 / 2 = 11번째 인덱스의 값인 12
3회전 12 + 14 / 2 = 13번째 인덱스의 값인 14 = 찾으려는 값
검색 알고리즘 (Search Algorithm)
#[?] 정렬되어 있는 데이터를 이진 검색(이분 탐색)을 사용하여 반씩 나눠서 검색
# 검색 알고리즘 (Search Algorithm) : 주어진 데이터에서 특정 데이터
def main():
#[1] Input
data = [1, 3, 5, 7, 9] # 몇 번만에 찾는지 이론적으로 알아야함 - 오름차순으로 정렬되었다고 가정
N = len(data) # 의사코드(슈도코드)
search = 3 # 검색할 데이터
flag = False # 플래그 변수 : 찾으면 True | 찾지 못하면 False
index = -1 # 인덱스 변수 : 찾은 위치 (인덱스를 -1로 놨을 때 false의 느낌)
#[2] Process : 이진 검색(Binary Search) 알고리즘 (devide and conquer) : Full Scan -> Index Scan
low = 0 # min : 낮은 인덱스
high = N - 1 # max : 높은 인덱스
while low <= high: # while : ~하는 동안
mid = (low + high) / 2 # 중간 인덱스 (mid) 구하기 : 핵심부분
if data[mid] == search: #중간 인덱스에서 찾기 : 데이터의 미드 인덱스가 서치랑 같은지 물어보는 것
flag = True; index = mid; break; # 찾으면 플래그, 인덱스 저장 후 종료
#[3] Output
if flag:
print(f"{search}을(를) {index}위치에서 찾았습니다.")
else:
print("찾지 못했습니다.")
if __name__=="__main__":
main()이 부분이 파이썬에서는 mid가 2.0(float 타입)으로 나옴 = index는 정수형 데이터로 나와야 하므로 추가사항이 있음
int 넣을 때 괄호가 추가됨(안넣으면 오류남)
#[?] 정렬되어 있는 데이터를 이진 검색(이분 탐색)을 사용하여 반씩 나눠서 검색
# 검색 알고리즘 (Search Algorithm) : 주어진 데이터에서 특정 데이터
def main():
#[1] Input
data = [1, 3, 5, 7, 9] # 몇 번만에 찾는지 이론적으로 알아야함 - 오름차순으로 정렬되었다고 가정
N = len(data) # 의사코드(슈도코드)
search = 3 # 검색할 데이터 - 내가 찾을 데이터를 입력하는 곳
flag = False # 플래그 변수 : 찾으면 True | 찾지 못하면 False
index = -1 # 인덱스 변수 : 찾은 위치 (인덱스를 -1로 놨을 때 false의 느낌)
#[2] Process : 이진 검색(Binary Search) 알고리즘 : Full Scan -> Index Scan
low = 0 # min : 낮은 인덱스
high = N - 1 # max : 높은 인덱스
while low <= high: # while : ~하는 동안
mid = int((low + high) / 2) # 중간 인덱스 (mid) 구하기 : 핵심부분
if data[mid] == search: #중간 인덱스에서 찾기 (데이터의 미드 인덱스가 서치랑 같은지 물어보는 것)
flag = True; index = mid; break; # 찾으면 플래그, 인덱스 저장 후 종료
if data[mid] > search:
high = mid - 1 # 찾을 데이터가 작으면 왼쪽 영역으로 이동
else:
low = mid + 1 # 찾을 데이터가 크면 오른쪽 영역으로 이동
#[3] Output
if flag:
print(f"{search}을(를) {index}위치에서 찾았습니다.")
else:
print("찾지 못했습니다.")
if __name__=="__main__":
main()코드는 괄호 하나만 잘못 넣어도 값이 제대로 안나오므로 잘 입력해야 함
병합 알고리즘의 이론적인 설명 및 의사 코드로 진행(중복 생략)
병합 알고리즘 및 병합 정렬 알고리즘(Merge Sort)의 이론 설명
1번 데이터 배열과 2번 데이터 배열을 비교해서 작은 값을 데려와서 오름차순으로 채우는 것
(한쪽이 끝나면 나머지 수는 자동으로 끝에 채워주는 알고리즘)
알고리즘은 단순한 노가다를 코드로 설정해서 노가다로 해도 빠른 컴퓨터에게 적용하는 과정같다.
(사람이 노가다로 하나하나하면 오래걸리지만 컴퓨터에게는 찰나이므로 그 단순한 노가다를 코드로 작성하여 단순 반복이 빠른 컴퓨터에게 사용할 수 있도록 제공하는 과정 느낌이 강했다.)
병합 알고리즘 (Merge Algorithm)
#[?] 2개의 정수 배열 합치기: 단, 2개의 배열은 오름차순으로 정렬되어 있다고 가정
# 병합 알고리즘(Merge Algorithm) : 오름차순으로 정렬되어 있는 정수 배열을 하나로 병합
def main():
#[1] input
first = [1, 3, 5] # 오름차순 정렬
second = [2, 4] # 오름차순 정렬
M = len(first); N=len(second); # M:N 관행
merge = [0] * (M + N) # 병합된 배열
i = 0; j = 0; k = 0; # i, j, k 관행
#[2] process : MERGE
while (i < M and j < N):
if first[i] < second[j]:
merge[k] = first[i]; k += 1; i += 1;
else:
merge[k] = first[i]; k += 1; i += 1;
while (i > M): # 첫 번째 배열이 끝까지 도달할 때까지
merge[k] = first[i]; k += 1; i += 1;
while (j < N): # 두 번째 배열이 끝까지 도달할 때까지
merge[k] = first[i]; k += 1; i += 1;
#[3] output
for item in merge:
print(item, end=", ")
print()
if __name__=="__main__":
main()이렇게 하면 뭐가 다른 것인지 잘 모르겠다. 이번 강의에서는 메인 함수를 사용하지 않았다.
#[?] 2개의 정수 배열 합치기: 단, 2개의 배열은 오름차순으로 정렬되어 있다고 가정
# 병합 알고리즘(Merge Algorithm) : 오름차순으로 정렬되어 있는 정수 배열을 하나로 병합
#[1] input
first = [1, 3, 5] # 오름차순 정렬
second = [2, 4] # 오름차순 정렬
M = len(first); N = len(second); # M:N 관행
merge = [0] * (M + N) # 병합된 배열
i = 0; j = 0; k = 0; # i, j, k 관행
#[2] process : MERGE
while (i < M and j < N): # 둘 중 하나라도 배열의 끝에 도달할 때까지
if first[i] < second[j]:
merge[k] = first[i]; k += 1; i += 1;
else:
merge[k] = first[j]; k += 1; j += 1;
while (i > M): # 첫 번째 배열이 끝까지 도달할 때까지
merge[k] = first[i]; k += 1; i += 1;
while (j < N): # 두 번째 배열이 끝까지 도달할 때까지
merge[k] = first[j]; k += 1; j += 1;
#[3] output
for item in merge:
print(item, end=", ")
print()왜 강의와 다른 값이 나오는 것인지..? 1, 1, 3, 3, 0 이 나온다.
(1, 2, 3, 4, 5가 나와야 하는데)

나중에 다시 한번 비교해봐야겠다.
최빈값 알고리즘 이론적인 설명 (의사코드로 진행) - 중복 생략
최빈값 : 가장 많은 빈도의 수
점수(DATA) - 인덱스(Index) - 횟수(COUNT) - 가장 많음(MAX) - 정리(MODE)
최빈값 알고리즘 (Mode Algorithm)
갑자기 메인 함수를 안쓰는데 왜 안쓰는 것인지와 안쓰는 것의 차이를 알려주지 않는다.(궁금하다)
len은 이전에서 사용하던 length가 파이썬에서는 len으로 표현하는 것인지?
length와 len의 의미는?
#[?] 주어진 데이터에서 가장 많이 나타난(중복된) 값
# 최빈값 알고리즘 (Mode Algorithm) : 점수 인덱스(0~n)의 개수(COUNT)의 최댓값(MAX)
import sys
#[1] Input
scores = [1, 3, 4, 3, 5] # 0 ~ 5 까지만 들어온다고 가정
indexes = [0] * (5 + 1) # 0 ~ 5까지 점수 인덱스의 개수 저장
max = -sys.maxsize -1 # MAX 알고리즘 적용
mode = 0 # 최빈값이 담길 그릇
#[2] Process : DATA -> Index -> Count -> Max -> Mode(최빈값)
for i in range(0, len(scores)):
indexes[scores[i]] = indexes[scores[i]] + 1 # COUNT
for i in range(0, len(indexes)):
if indexes[i] > max:
max = indexes[i] # MAX
mode = i # MODE
#[3] Output
print(f'최빈값: {mode} -> {max}번 나타남')마찬가지로 프로세스 부분을 외우면 좋음
그룹 알고리즘 이론 (의사코드로 진행) - 중복 생략
간단하게 말해 원본 데이터에 있는 내용 중 Radio:3, TV:1, Radio:2, DVD 4일 때 정렬 후 모두 합쳐서 나오는 것이
그룹 알고리즘
기본데이터
| Radio | 3 |
| TV | 1 |
| Radio | 2 |
| DVD | 4 |
그룹 알고리즘 적용 후 (Name Sort & Sum & Merge) = Group Algorithm
| DVD | 4 |
| Radio | 5 |
| TV | 1 |
그룹 알고리즘 (Group Algorithm)
r.name, rjust 등 갑자기 나오는 언어에 대한 설명이 없어서 매우 불친절한 강의다.
나중에 알고리즘 부분은 유튜브를 보던가 공부를 다시해야할 것 같다.
너무 그냥 쓰는것 보는 것이라 이해가 안간다.
이 부분의 프로세스 부분은 매우 중요
SORT 부분과 GROUP 부분으로 나눠놓았음
#[?] 컬렉션 형태의 데이터를 특정 키 값으로 그룹화
# 그룹 알고리즘(Group Algorithm) : 특정 키 값에 해당하는 그룹화된 합계(소계) 리스트 만들기
# 테스트용 레코드 클래스
class Record():
def __init__(self, name, quantity):
self.name = name # 상품명
self.quantity = quantity # 수량
def main():
#[1] Input
records = [ Record("RADIO", 3), Record("TV", 1), Record("RADIO", 2), Record("DVD", 4)] # 입력 데이터
groups = [] # 출력 데이터
N = len(records) # 의사코드
#[2] Process : GROUP 알고리즘 (SORT -> SUM -> GROUP)
#[A] 그룹 정렬 : SORT - Selection Sort
for i in range(N - 1):
for j in range(i + 1):
if (records[i].name > records[j].name):
temp = records[i]
records[i] = records[j]
records[j] = temp # SWAP
#[B] 그룹 합계(소계) : GROUP
subtotal = 0 # 합계(소계) - 중복되는 값이 합쳐지는 곳
for i in range(N):
subtotal = subtotal + records[i].quantity # 같은 상품명의 수량을 누적(SUM)
#[!] 다음 레코드가 없거나, 현재 레코드와 다음 레코드가 다르면 저장
if ((i + 1) == N or records[i].name !=records[i + 1].name):
# (한 그룹의 키(Key) 지정, 합계(소계))
groups.append(Record(records[i].name, subtotal)) # 하나의 그룹 저장
subtotal = 0 # 하나의 그룹이 완료되면 소계 초기화
#[3] Output
print("[1] 정렬된 원본 데이터:")
for r in records:
print(f"{r.name.rjust(6)} - {r.quantity}")
print("[2] 이름으로 그룹화된 데이터:")
for g in records:
print(f"{g.name.rjust(6)} - {g.quantity}")
if __name__=="__main__":
main()왜 결과값이 이상하게 나오는지 모르겠다.

나중에 비교를 위해 아래에 정상적인 코드 저장



댓글